转自知乎,写得太好了哇!https://zhuanlan.zhihu.com/p/106459445
持久性的数据是存储在外部磁盘上的,如果没有文件系统,访问这些数据就需要直接读写磁盘的sector,实在太不方便了。而文件系统存在的意义,就是能更有效的组织、管理和使用磁盘上的这些raw data。
文件系统的组成
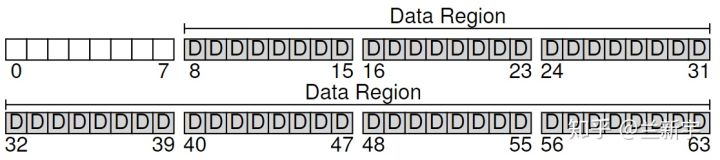
要管理,就得先划分,那按照什么粒度划分呢?因为磁盘上的数据要和内存交互,而内存通常是以4KB为单位的,所以从逻辑上,把磁盘按照4KB划分比较方便(称为一个block)。现在假设由一个文件系统管理64个blocks的一个磁盘区域:
empty disk:

那在这些blocks中应该存储些什么?文件系统的基础要素自然是文件,而文件作为一个数据容器的逻辑概念,本质上是一些字节构成的集合,这些字节就是文件的user data(对应下图的”D”)。
user data:
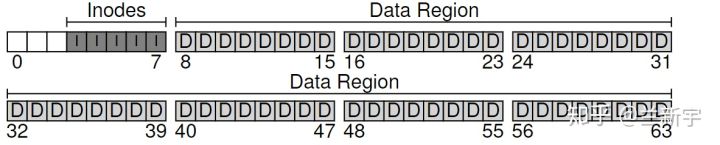
除了文件本身包含的数据,还有文件的访问权限、大小和创建时间等控制信息,这些信息被称为meta data。meta data可理解为是关于文件user data的data,这些meta data存储的数据结构就是inode(对应下图的”I”,有些文件系统称之为dnode或fnode)。
inode是”index node”的简称,在早期的Unix系统中,这些nodes是通过数组组织起来的,因此需要依靠index来索引数组中的node。假设一个inode占据256字节,那么一个4KB的block可以存放16个inodes,使用5个blocks可以存放80个inodes,也就是最多支持80个文件。
meta data + user data:
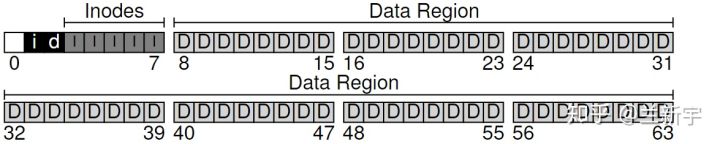
同内存分配一样,当有了新的数据产生时,我们需要选择一个空闲的block来存放数据,此外还需要一个空闲的inode。所以,需要追踪这些inodes和data blocks的分配和释放情况,以判断哪些是已用的,哪些是空闲的。
最简单的办法就是使用bitmap,包括记录inode使用情况的bitmap(对应下图的”i”),和记录data block使用情况的bitmap(对应下图的”d”)。空闲就标记为0,正在使用就标记为1。
bitmap + meta data + user date:
因为block是最小划分单位,所以这里使用了两个blocks来分别存储inode bitmap和data block bitmap,每个block可以容纳的bits数量是4096*8。而这里我们只有80个inodes和56个data blocks,所以是绰绰有余的。
还剩下开头的一个block,这个block是留给superblock的(对应下图的”S”)。
superblock + bitmap + meta data + user date:
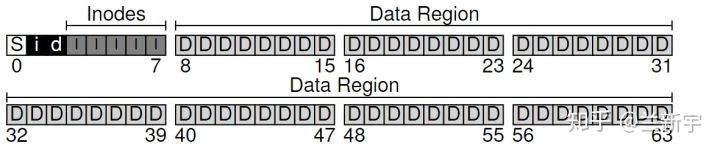
这个superblock包含了一个文件系统所有的控制信息,比如文件系统中有多少个inodes和data blocks,inode的信息起始于哪个block(这里是第3个),可能还有一个区别不同文件系统类型的magic number。因此,superblock可理解为是文件系统的meta data。
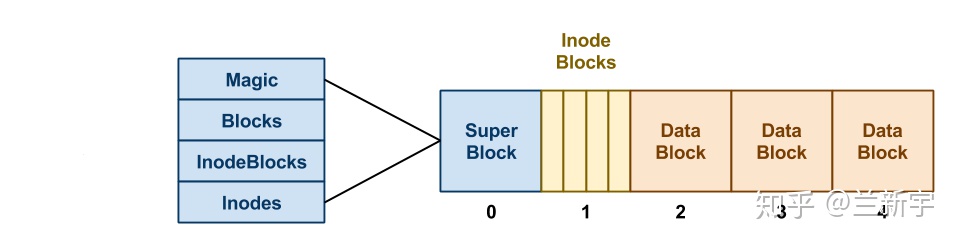
文件寻址
这5个blocks中的80个inodes构成了一个inode table。假设一个inode的大小是256字节,现在我们要访问第32个文件,那就要先找到这个文件的控制信息,也就是第32个inode所在的磁盘位置。它应该在相对inode table起始地址的8KB处(32*256=8192),而inode table的起始地址是12KB,所以实际位置是20KB。
inode table:

磁盘同内存不同,它在物理上不是按字节寻址的,而是按sector。一个sector的大小通常是512字节,因此换算一下就是第40个sector(20*1024/512)。
对于ext2/3/4文件系统,以上介绍的这些inode bitmap, data block bitmap和inode table,都可以通过一个名为“dumpe2fs”的工具来查看其在磁盘上的具体位置:
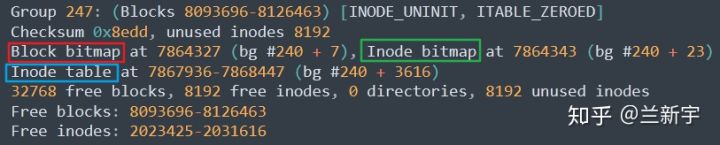
如果只需要查看inode的使用情况,那么直接使用”df -i”命令即可:

寻址方式
那通过inode如何找到对应的文件呢?根据大小的不同,一个文件需要占据若干个blocks,这些blocks可能是磁盘上连续分布的,也可能不是。所以,比较好的办法是使用指针,指针存储在inode中,一个指针指向一个block。
不过,在这个简化的示例里,并不需要C语言里那种指针,只需要一个block的编号就可以了。如果文件比较小,占有的blocks数目就比较少,那么一个256字节的inode就能存储这些指针。假设一个inode最多能包含12个指针,那么文件的大小不能超过48KB。
那如果超过了怎么办?可由inode先指向一个block,这个block再指向分散的data block,这种方法称为multi-level index。inode在指向中间block的同时,也可以直接指向data block。假设一个指针占据4个字节,那么一个中间block可存储1024个指针,二级index的寻址范围就可超过4MB,三级index则可超过4GB。
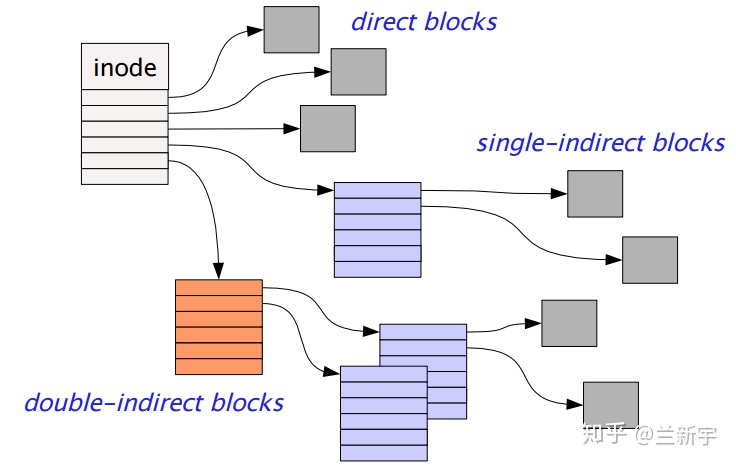
有没有觉得很像内存管理中的多级页表?事实上,它们的原理可以说是一样的,文件在磁盘上的实际block分布对等于内存的物理地址,而各级index就对等于内存的虚拟地址。
这种只使用block指针的方式被ext2和ext3文件系统所采用,但它存在一个问题,对于各种大小的文件,都需要较多的meta data。而在实际的应用中,大多数文件的体积都很小,meta data相对user data的占比就较大。
另一种实现是使用一个block指针加上一个length来表示一组物理上连续的blocks(称为一个extent,其中length以block为单位计),一个文件由若干个extents构成。这样,小文件所需要的meta data就较少,这种更灵活的实现方式被后来的ext4文件系统所采用。
struct ext4_extent {
__le32 ee_block; /* first logical block extent covers */
__le16 ee_len; /* number of blocks covered by extent */
...
};
目录和路径
各级目录构成了访问文件的路径,不同于windows操作系统的drive分区,类Unix系统中的”mount”操作让所有的文件系统的挂载点都是一个路径,形成了树形结构。从抽象的角度,目录也可视作一种文件,只是这种文件比较特殊,它的user data存储的是该路径下的普通文件的inode编号。
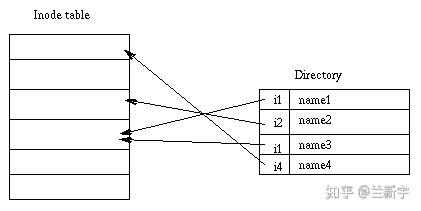
所以,如下图所示的这样一个路径结构,假设要在”/foo”目录下创建一个文件”bar.txt”,那么需要从inode bitmap中分配一个空闲的inode,并在”/foo”这个目录中分配一个entry,以关联这个inode号。
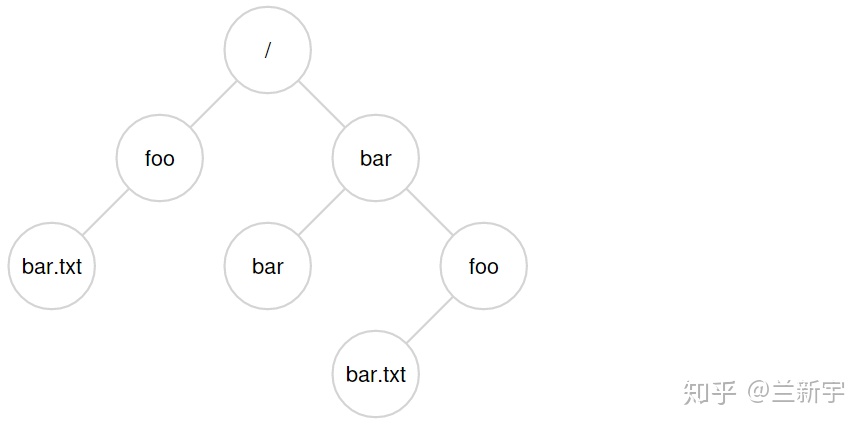
接下来,我们要读取刚才创建的这个”/foo/bar.txt”文件,那么先得找到”/”这个目录文件的inode号(这必须是事先知道的,假设是2)。然后访问这个inode指向的data block,从中找到一个名为”foo”的entry,得到目录文件”foo”的inode号(假设是44)。重复此过程,按图索骥,直到找到文本文件”bar.txt”的inode号。
小结
现代文件系统的实现是很庞杂的,但文件系统的原理本身并不深奥,基本的构成要素就是file data,管理各个文件的inode和管理整个文件系统的superblock。基于这些要素,下文将开始介绍读写一个文件的具体方式和接口。
PS:所谓持久性(persistance),就是指即便面对困难、挑战,依然可以持续,对于设备来说,就是面对掉电、操作系统crash,依然可以保持数据的持久存在!
这样一来,我终于知道文件系统是为何而生,又是如何工作的了!文件系统其实就是一个管理硬盘等硬件的上层结构。但是网络信息等,又是怎么虚拟成文件系统的呢?VFS又是什么呢?