为什么要进行内存对齐
在计算机组成原理中我们学到:一块内存芯片一般只提供 8 位数据线,要进行 16 位数据的读写可采用奇偶分体来组织管理多个芯片,32 位也类似:
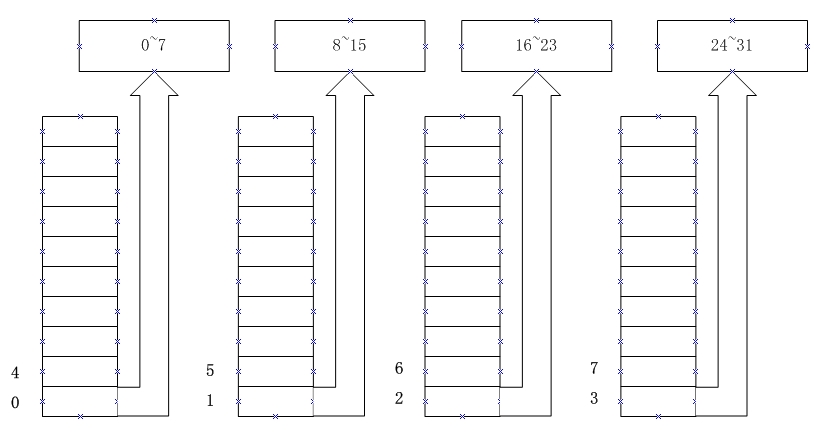
这样,连续的四个字节会分布在不同的芯片上,送入地址 0,我们可将第 0、1、2、3 四个字节一次性读出组成一个 32 位数,送入地址 4(每个芯片接收到的地址是1),可一次性读出 4、5、6、7 四个字节。
但是如果要读 1、2、3、4 四个字节,就麻烦了,有的 CPU 直接歇菜了:我处理不了!但 Intel 的 CPU 走的是复杂指令集路线,岂能就此认输,它通过两次内存读,然后进行拼接合成我们想要的那个 32 位数,而这一切是在比机器码更低级的微指令执行阶段完成的,所以 movl 1, %eax 会不出意外地读出 1、2、3、4 四个字节到 eax,证据如下(mem.c):
#include <stdio.h>
char a[]={0x11, 0x22, 0x33, 0x44, 0x55, 0x66, 0x77, 0x88};
int main()
{
int *p = (int*)(a + 1);
int ans = *p;
printf("*p:\t%p\n", ans);
printf("a:\t%p\n", a);
printf("p:\t%p\n", p);
return 0;
}
该程序的运行结果如下:
[lqy@localhost temp]$ gcc -o mem mem.c
[lqy@localhost temp]$ ./mem
*p: 0x55443322
a: 0x80496a8
p: 0x80496a9
[lqy@localhost temp]$
可看出程序确实从一个未对齐到 4 字节的地址(0x80496a9)后读出了 4 个字节,从汇编可看出确实是 1 条 mov 指令读出来的:
movl $a, %eax
addl $1, %eax
movl %eax, 28(%esp) # 初始化指针 p
movl 28(%esp), %eax
movl (%eax), %eax # 这里读出了 0x55443322
movl %eax, 24(%esp) # 初始化 ans
虽然 Intel 的 CPU 能这样处理,但还是要浪费点时间不是,所以 C 程序还是要采取措施避免这种情况的发生,那就是内存对齐。
内存对齐的结果
内存对齐的完整描述你还是去百度吧,这里我只是含糊地介绍一下:
- 保证最大类型对齐到它的 size
- 尽量不浪费空间
比如:
struct A{
char a;
int c;
};
它的大小为 8,c 的内部偏移为 4, 这样就可以一次性读出 c 了。
再如:
struct B{
char a;
char b;
int c;
};
它的大小还是 8,第 2 条起作用了!
关闭内存对齐
讲到内存对齐,估计大家最期待的一大快事就是怎么关闭它(默认是开启的),毕竟 Intel CPU 如此强大,关闭了也没事。
关闭它也甚是简单,添加预处理指令 #pragma pack(1) 就行,windows linux 都管用:
#include <stdio.h>
#pragma pack(1)
struct _A{
char c;
int i;
};
//__attribute__((packed));
typedef struct _A A;
int main()
{
printf("%d\n", sizeof(A));
return 0;
}
gcc 中更常见的是使用 __attribute__((packed)),这个属性只解除对一个结构体的内存对齐,而 #pragma pack(1) 解除了整个 C源文件 的内存对齐,所以有时候 __attribute__((packed)) 显得更为合理。
什么时候可能需要注意或者关闭内存对齐呢? 我想大概是这两种情况:
- 结构化文件的读写
- 网络数据传输
另一个浪费内存的家伙
说到内存对齐,我想起了另一个喜欢浪费内存的家伙:参数对齐(我瞎编的名字,C 标准中或许有明确规定)。 看下面这个程序:
#include <stdio.h>
typedef unsigned char u_char;
u_char add(u_char a, u_char b)
{
return (u_char)(a+b);
}
int main()
{
u_char a=1, b=2;
printf("ans:%d\n", add(a, b));
return 0;
}
你说 add 函数的参数会占几个字节呢?2个?4个? 结果是 8 个……
“可恨”的是,这个家伙浪费内存的行为却被所有编译器纵容,我们无法追究它的责任(应该是为了方便计算参数位置而规定的)。